Transform Unstructured Data for AI Applications
An open-source ingestion pipeline designed to transform unstructured data into vectorized formats for integration with knowledge bases

Automated Deployment to AWS with Splinter CLI Tool
Splinter is built using AWS architecture and can be easily deployed using the CLI tool. The self-managed, serverless design makes it especially useful for organizations seeking both scalability and control over their unstructured data pipelines.
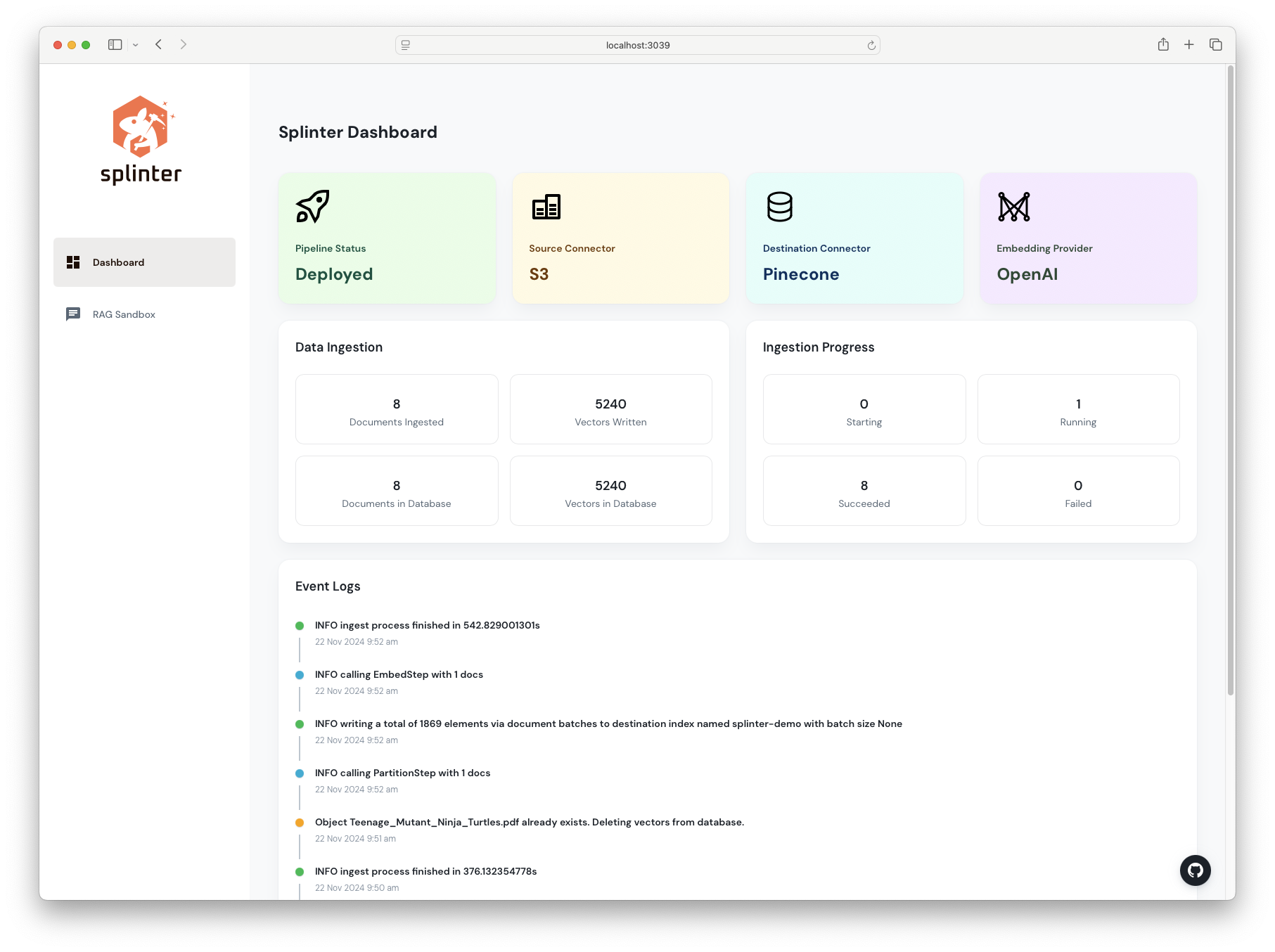
Data Pipeline Observability
The dashboard offers real-time updates during the ingestion process, including the current state of each document’s ingestion, the number of existing vectors, and the number of new vectors added to the knowledge base.

RAG Sandbox
The built-in RAG system uses the user’s destination database as its knowledge base. It updates its context based on the documents in the knowledge base, allowing users to verify the accuracy of the ingested data through direct queries.
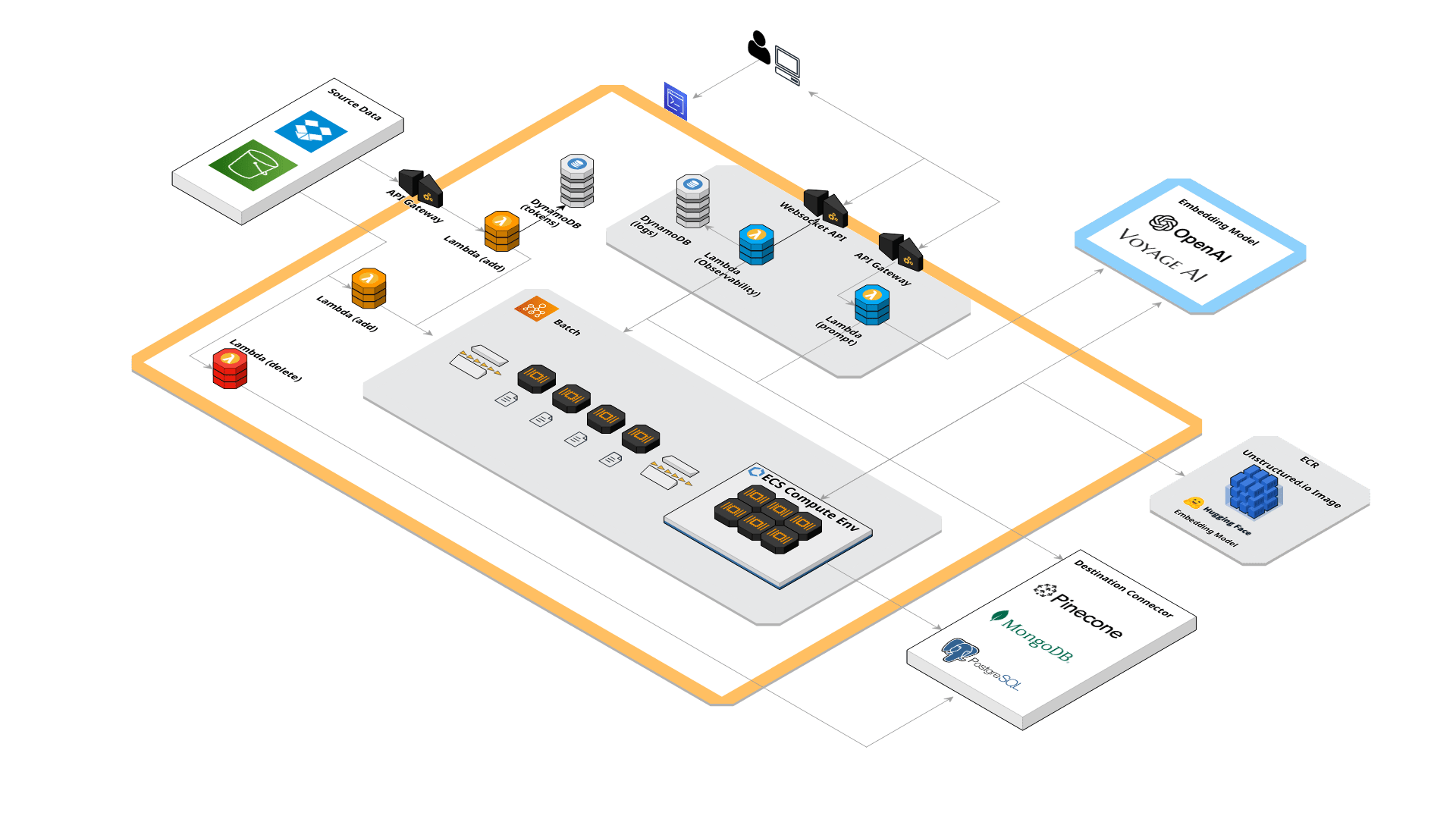
Event-Driven and Ephemeral Architecture
Splinter synchronizes data sources like AWS S3 or Dropbox with the destination database, automatically updating whenever documents are added, updated, or removed. Splinter’s ephemeral, event-driven design ensures that it "scales to zero," eliminating costs for idle compute resources.
Meet the Team

Amir Sadeghifar
Software Engineer
Miami, FL



Brian Ouyang
Software Engineer
Los Angeles, CA

Harold Camacho
Software Engineer
Toronto, Canada
Ricardo Delgado
Software Engineer
Houston, TX